8 Suchmaschinen und Discovery-Systeme Teil 1
Suchmaschinen & Discovery-Systeme Teil 1
Bevor es mit dem eigentlichen Thema des 8. BAIN-Tages losgeht, werden nachstehend noch einige Thematiken der letzten Vorlesung mit Hinweisen und weiterführenden Aspekten ergänzt damit alles von mir angesprochene – soweit möglich – vollständig ist.
OpenRefine:
Das angedeutete Template-Fenster-Problem kann durch das Öffnen von OpenRefine in einem neuen Browser-Tab umgangen werden. So können im neuen Tab mit ‘Edit cells > Transform’ Änderungen gemacht, respektive Funktionen, Inhalte oder was auch immer von Interesse ist, nachgesehen und ausprobiert werden. Bleibt zu hoffen, dass in der nächsten Version das Fenster nicht komplett neu geladen wird und somit die Eingabe nicht verloren geht. Ausserdem hat die Lösung der lobid-gnd Anreichunergs-Aufgabe (noch offen) gezeigt, dass in OpenRefine hierarchische Strukturen in Tabellenform umständlich und komplex in ihrer Verarbeitung sind. Fazit: OpenRefine ist ein spannendes Tool, das – wie alle Systeme (:-)) – Fachwissen über Funktionen, Möglichkeiten und Grenzen voraussetzt damit die Datensätze nicht „zerschossen“ werden.
XML-Validierung & Deklaration:
Für die Validierung einer XML-Datei haben wir in der Vorlesung das Programm ‚xmllint‘ genutzt, das bereits vorinstalliert ist in Ubuntu. Das offizielle Schema (XSD) von MARC21 muss für den Abgleich heruntergeladen werden. Bei der letzten Vorlesung hatten wir am Schluss per Export-Button eine Datei exportiert, die wir jetzt lokal in einem Verzeichnis auf der VM abgespeichert haben wollen. Mit *.xml wird das für alle XML-Dateien gemacht – es könnte jedoch auch ein spezifischer Dateinamen angegeben werden um nur diese eine Datei zu validieren. Mit dem –noout - - wird schlussendlich nur die Validierung ausgegeben und nicht die ganze Datei.
In der Shell einzugeben ist also folgendes:
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
xmllint *.xml --noout --schema MARC21slim.xsd
Zu Beginn einer XML-Datei wird für die Programme, die dann damit arbeiten sollen, angegeben, dass es sich um eine XML-Datei handelt. Das sieht so aus (Reihenfolge der Attribute ist fix und so vorgegeben):
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
Die spitzen Klammern und ‘xml’ geben an, um was für eine Datei es sich handelt. Danach folgt eine Versionsangabe (es gibt nur 2 Versionen ;)), die es unbedingt zu deklarieren gilt. Daraufhin wird die Zeichencodierung angegeben (hier Standard Unicode) und auf eine allfällige DTD verwiesen. Diese Angaben sind im Gegensatz zur Versionsangabe keine Pflicht, gehören aber zur guten Praxis.
Weitere Tools zur Metadatentransformation
Vergleich mit anderen Tools
Grundsätzlich ist die Wahl der für die jeweilige Institution/Organisation passenden Software stark von dessen Einsatzbereiche, konkreten Anwendungsfällen und natürlich auch von den zur Verfügung stehenden Ressourcen abhängig.
Hier nochmals die Merkmale von OpenRefine in zusammenfassender Auflistung:
- Grafische Oberfläche: Transformationsergebnisse werden direkt sichtbar
- Skriptsprachen (GREL, Jython, Clojure) für komplexe Transformationen
- Schwerpunkt auf Datenanreicherung (Reconciliation)
Alternative Software wären bspw. Catmandu (Perl), Metafacture (Java), MarcEdit (für MARC21)
LIDO – ein Metadatenstandard für den Museumsbereich
LIDO steht für Lightweight Information Describing Objects und dient der Beschreibung von Kulturobjekten. Basis für den XML-Standard ist das CIDOC Conceptual Reference Model (CRM), das sehr abstrakt ist und mittels URI-Definitionen für Entitäten und Relationen funktioniert. Die Terminologie von LIDO ist also CIDOC CRM orientiert. Durch die spezielle Struktur ist eine verlustfreie Transformation in andere Formate jedoch äusserst schwierig. Denn die Besonderheit von LIDO ist die ereignis-zentrierte Beschreibung von Objekten und die Kontextherstellung zwischen zwei Entitäten. Wenn also Entitäten am gleichen Ereignis „beteiligt“ sind, dann muss dessen Beziehung miteinander nicht explizit definiert werden. Dieses Beziehungsgeflecht droht jedoch bei Transformationen verloren zu gehen. Lido wird nicht per se in allen Museen eingesetzt, sondern wird einfach als Austauschformat genutzt auch mit anderen Plattformen.
LIDO - Struktur
- deskriptive Metadaten:
- Identifikation (Titel/Name, Beschreibung, Maße, etc.)
- Klassifikation (Art, Gattung, Form, etc.)
- Ereignisse (Herstellung, Bearbeitung, Besitzwechsel, Restaurierung, etc.)
- Relationen (Objekte, Personen, Orte, etc.)
- administrative Metadaten:
- Rechte (Objekt, Datensatz, Nutzung, Verbreitung, etc.)
- Datensatz (Identifikation, Urheber, etc.)
- Ressourcen (Digitalisat, Nachweis, etc.)
Suchmaschinen und Discovery-Systeme Teil 1
Wie auch in der Modulübersicht (Schaubild) sichtbar, werden wir VuFind kennen lernen. Die Installation der Software wurde gemeinsam Schritt für Schritt nach der offiziellen Anleitung in Ubuntu durchgearbeitet. Als kleiner Reminder betreffend Installationen: am besten wäre nur eine Software pro Server zu installieren. Dies ist heutzutage durch Virtualisierung und mittels Container einfach möglich. Unser Server ist etwas „vorbelastet“ mit ArchivesSpace, OpenRefine und allem was wir bis jetzt installiert haben. Anyway, die Auto-Konfiguration und die Installation hat bei mir geklappt :)
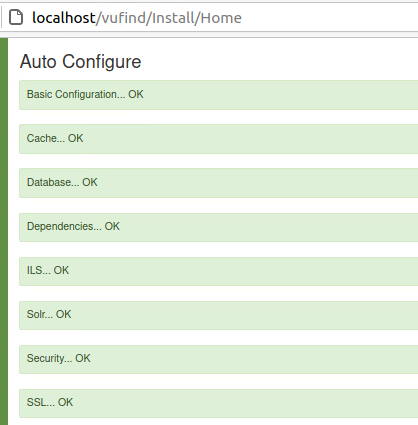
mit den Bemerkungen und Hinweisen im Skript helfen enorm um die Schritte auch zu verstehen. „Anschließend sollten in der Suchoberfläche unter http://localhost/vufind ca. 250 Datensätze enthalten sein.“
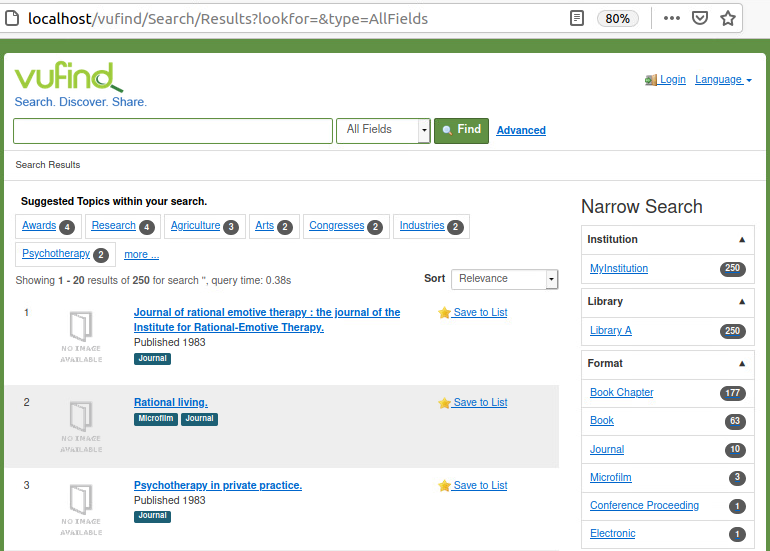
Die Konfiguration von VuFind war wegen der bereits sehr fortgeschrittenen Zeit als Aufgabe vor der nächsten Vorlesung mit Hilfe eines Videos vorzubereiten.